Generische Filiale / Schnittstelle
Zuletzt aktualisiert am 28. Februar 2024
Die Generische Filiale ist eine frei konfigurierbare Universalschnittstelle für Datenimport und Datenexport.
Allgemeines zur Generischen Filiale
Die Generische Filiale ist:
• Individualisierbar, flexibel.
• Vielseitig verwendbar, einsetzbar bzw. anpassbar.
• hat einen hohen Abstraktionsgrad.
• mit allgemeine Funktionen ausgestattet, um für unterschiedliche Datentypen und Datenstrukturen verwendet werden zu können.
Generische Filiale (Generischer Import/Export) in Bezug auf VARIO:
• Frei definierbare Datenimporte und Datenexporte (Formate: .xml, .csv, .xls(x) (für Excel-Formate muss auf dem PC Excel installiert und lizensiert sein)) mit Zugriff auf Dateiverzeichnisse und optionalen Dateiaustausch über FTP und SFTP.
• Intervall der automatischen Verarbeitung einstellbar.
• Voraussetzung: Mindestens eine Webshop-Filiale (für evtl. Auftragsimport).
Das Dateiformat wird dabei vom Kunden spezifiziert, bzw. vom Partner mit dem die Daten ausgetauscht werden sollen (Schnittstellenbeschreibung).
Die große Stärke dieses Konzepts ist es, dass Daten direkt passend bereitgestellt werden, damit sie in ein anderes Programm importiert werden können. Die meisten anderen Programme geben ein festes Dateiformat vor und es wird ein zusätzliches Programm bzw. ein Dienstleister benötigt, der sich um die Datenkonvertierung kümmert. Dieser Aufwand entfällt bei der VARIO (Ausnahmen: EDIFACT und BTE, siehe unten).
Über an die natürliche Sprache angelehnte Regeln lässt sich zusammen mit der Replikationsanwendung eine umfangreiche Zeitsteuerung für die Importe/Exporte umsetzen.
Ein Log zur Ausführung der sogenannten Mappings, ein Ausgabebereich, der z.B. eingelesene Werte anzeigt, sowie die Einsortierung der zugrundeliegenden Dateien in ein Haupt-, ein Archiv- und ein Problemverzeichnis dienen als Werkzeuge für Analysen und Fehlersuche.
Die Generische Filiale hat Zugriff auf alle Datenbanktabellen, daher können sämtliche Daten aus VARIO importiert bzw. exportiert werden.
Die häufigsten Anwendungsfälle sind:
• Artikeldaten
• Lagerstände
• Preislisten
• Belege (Aufträge, Lieferscheine, Rechnungen)
• Adressdaten
• Export von Bildern für Online Shops
• Logistiksysteme/Versanddienstleister
Dateiformate:
• XML
• CSV
• Excel
• EDIFACT (in Kooperation mit einem EDI-Dienstleister)
• Bilder (nur als Export)
Übertragungswege:
• FTP
• SFTP
• http
• Netzlaufwerke
• Lokale Verzeichnisse
EDIFACT nur mit EDI-Dienstleister möglich
EDIFACT-Formate können wir nur mit einem EDI-Dienstleister (den der Kunde prinzipiell frei wählen kann) realisieren. Hierfür müssen die EDIFACT Dateien in ein für uns lesbares Format (XML, CSV, TXT) umgewandelt werden um verarbeitet werden zu können.
Kundeninformationen
Grundsätzlich stehen dem Kunden alle Werkzeuge zur Verfügung, die wir beim Erstellen der Konfigurationen nutzen, so dass er selbst die Mappings erstellen und bearbeiten kann, allerdings raten wir auf Grund der Mächtigkeit und Komplexität der Schnittstelle davon ab.
Da wir Anfragen mit den unterschiedlichsten Formaten bekommen können wir keine pauschalen Aussagen zu den Preisen machen. Wir benötigen vom Kunden Beispieldaten bzw. eine Spezifikation des Dateiformats, um ein individuelles Angebot erstellen zu können. Der Kunde benötigt einen Pflegevertrag, da für die Nutzung der generischen Filiale stets die aktuellste VARIO-Version benötigt wird.
Die Kundenbetreuung erfolgt je nach Komplexität durch das Consulting oder die Entwicklung. Eine Unterstützung durch die Hotline ist bei dieser Komplexität schlicht nicht möglich. Es handelt sich somit um ein eigenständiges Projekt, dem Kunden wird ein Projektleiter zugewiesen, welcher sich um die nötigen Konfigurationen kümmert. Ist das Modul “Generische Filiale” einmal erworben, können beliebig viele dieser Universalschnittstellen genutzt werden.
Ablauf der Umsetzung
Aufgrund der vielfältigen Formate und Anforderungen werden die Anbindungen in Form individueller Projekte umgesetzt, welche grob dem folgenden Ablauf folgen:
1. Anforderungserhebung
Zunächst erarbeitet ein Projektbetreuer mit dem Kunden die Anforderungen des Projekts.
• Mit wem sollen Daten ausgetauscht werden? Wie viele Gegenstellen gibt es?
• Welche Daten sollen übertragen werden? Belege, Artikeldaten, Adressen?
• Welches Datenformat soll benutzt werden?
• Wie sollen die Daten übertragen werden?
2. Angebotserstellung
Nach der Sichtung der Beispieldaten bzw. Spezifikation des Dateiformates werden ein individuelles Angebot und ggf. ein Zeitplan erstellt.
3. Technische Umsetzung
Im Anschluss an die Auftragserteilung folgt die technische Umsetzung der Schnittstelle. Dazu werden Dateibeschreibungen erstellt, welche definieren, wie die Daten von der generischen Filiale verarbeitet werden müssen.
4. Testphase
Sobald die technische Umsetzung bzw. die Mappingdatei bereit ist, folgt ein Testbetrieb, der dazu dient, eventuelle Probleme aufzudecken und die Mitarbeiter des Kunden mit der neuen Schnittstelle vertraut zu machen.
5. Live Betrieb
Nach der erfolgreichen Testphase folgt der Livebetrieb im normalen Alltagseinsatz.
6. Wartung/Pflege
Die Anbindung ist nicht in Stein gemeißelt. Sollten sich neue Anforderungen ergeben oder durch neue Programmversionen beim Geschäftspartner Änderungen erforderlich werden, so sind durch unsere Kundenbetreuer jederzeit Anpassungen möglich, um darauf zu reagieren.
Fragenkatalog
Für die Erstellung eines Zeit- und Kostenplans sind einige Informationen notwendig, die mit folgendem Fragenkatalog erarbeitet werden können.
Welche Gegenstellen gibt es?
Als Gegenstelle zählt jede Firma und jedes Programm/Webdienst, mit dem Daten ausgetauscht werden sollen.
Es wird eine Liste mit allen Gegenstellen und ihren Rollen benötigt, z.B:
• Firma A (Großkunde)
• Firma B (Lieferant)
• Programm XY (Adressbuch der Telefonanlage)
Für die Erstellung der generischen Mappings ist eine ausreichende Informationslage bzgl. Rollen, Objekten, Stellen, etc. erforderlich.
Welche Daten sollen ausgetauscht werden?
An dieser Stelle werden für jede Gegenstelle eine Liste der Nachrichtentypen und die Richtung der Übertragung benötigt.
Firma A (Großkunde)
• Import von Bestellungen
• Export von Lieferscheinen
• Export von Rechnungen
• Export von Bestandsmeldungen
Firma B (Lieferant)
• Export von Bestellungen
• Import von Artikelbeschreibungen
• Import von Rechnungen
Programm XY (Adressbuch der Telefonanlage)
• Export der Ansprechpartner mit ihren Telefonnummern
Wie sieht das Dateiformat aus?
Um die Komplexität des Dateiformats und damit den Arbeitsaufwand bei der Umsetzung abschätzen zu können, wird für jede Nachricht (also jeden Punkt der oberen Liste) eine Beispieldatei oder eine Beschreibung des Dateiformats benötigt.
Wie werden die Daten übertragen?
Neben der Frage, welches Protokoll für die Übertragung verwendet wird, ist gegebenenfalls auch die Frage zu klären, wer den Server bereitstellt.
• Firma A (Großkunde): Es wird der FTP-Server des VARIO-Nutzers verwendet.
• Firma B (Lieferant): Es wird der SFTP-Server des Lieferanten verwendet.
• Programm XY (Adressbuch der Telefonanlage): Die Daten werden auf einem Netzlaufwerk abgelegt.
Beim Streckengeschäft:
Werden Reporte benötigt, um Lieferscheine/Rechnungen im Design der Partnerfirma zu drucken?
Gegebenenfalls sind noch organisatorische Punkte zu klären:
• Bereitstellung des Servers für den RS.
• Einbindung der Schnittstelle in die Firmenabläufe.
• Schulung der Mitarbeiter.
Einrichtung
Anlegen einer neuen Filiale
Öffnen Sie den Menüpunkt “Filialen verwalten” in Ihrer VARIO unter Stammdaten – Filialen/Verkaufskanäle.
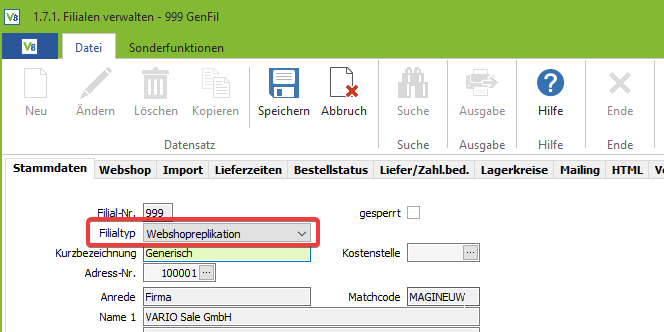
Legen Sie eine neue Filiale an und wählen den Filialtyp “Webshopreplikation” aus. Vergeben Sie eine Kurzbezeichnung und wählen die zugehörige Adresse Ihrer Filiale aus:
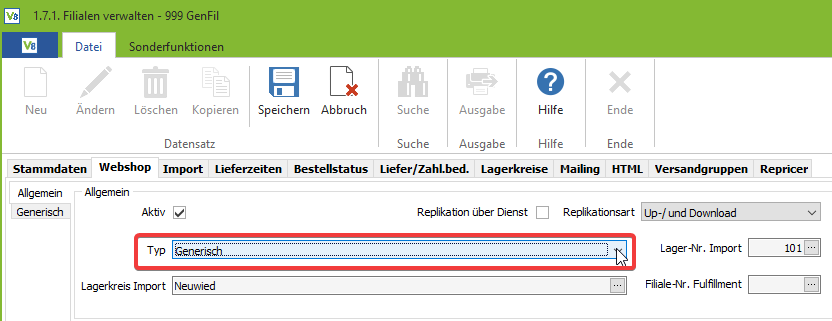
Wechseln Sie in den Reiter “Webshop” und wählen Sie den Webshoptyp “Generisch“. Des Weiteren müssen Sie noch eine Lager-Nr. und den Lagerkreis für den Import auswählen:
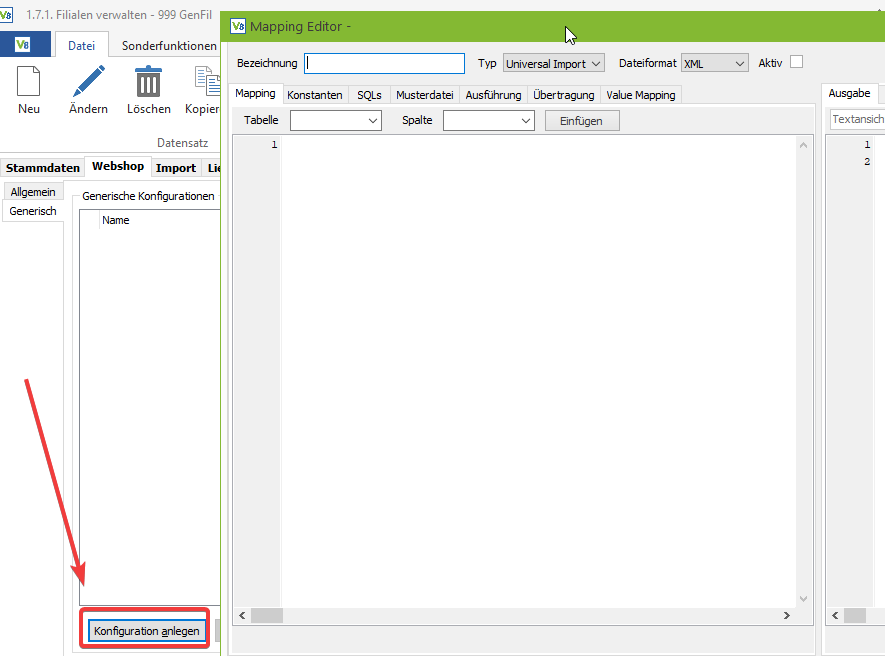
Nach dem Speichern der Filiale müssen die entsprechenden Konfigurationen angelegt werden. Diese sind bei jedem Anwendungsfall unterschiedlich. Beim Klick auf “Konfiguration anlegen” öffnet sich der Mapping-Editor:
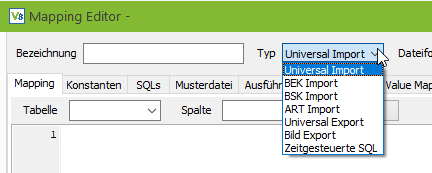
Es gibt verschiedene Konfigurationstypen, zu welchen Sie Mappings, Konstanten oder SQL’s hinterlegen können:
Im Reiter “Ausführung” kann die Zeitsteuerung vorgenommen werden:
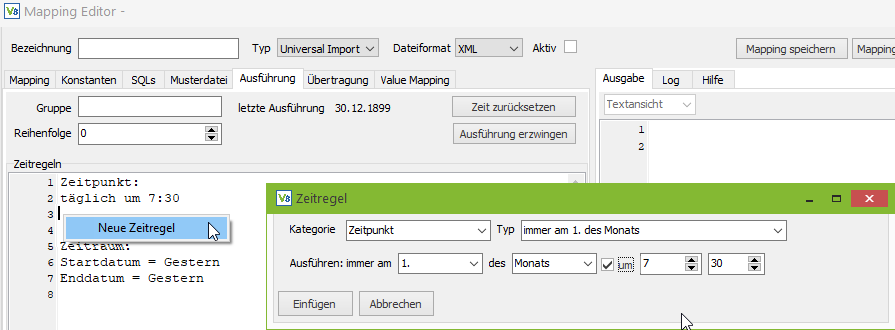
Grundlagen des Mappingeditors
Das zentrale Werkzeug zum Erstellen und Bearbeiten der Mappings ist der Mappingeditor.
Der Mappingeditor lässt sich grob in drei Bereiche aufteilen:
• Die obere Leiste.
• Den linken Teil mit Tabs zum Definieren des Mappings..
• Den rechten Teil für Hilfe, Ausgabe und Log.
Zunächst ist hier die obere Leiste interessant, die einige elementare Funktionen und Einstellungen enthält.
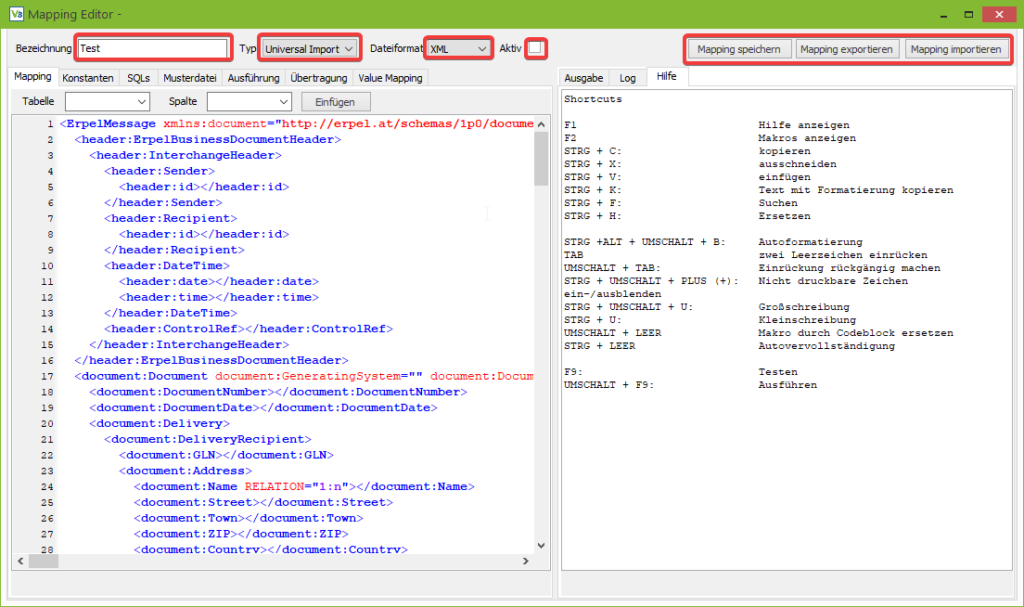
Über die ersten drei rot eingefärbten Felder werden der Name und die Art des Mappings definiert. Der Typ des Mappings und das Dateiformat sind elementar, damit der Mappingeditor die richtigen Tabs anzeigt.
Der Name hat für die Verarbeitung keine Relevanz, allerdings sollte er trotzdem sinnvoll gewählt werden, da er zum Anzeigen des Mappings in der Mappingverwaltung dient.
Die Checkbox in der Mitte der Leiste (“Aktiv”) dient zum Aktivieren bzw. Deaktivieren des Mappings. Deaktivierte Mappings werden vom Replikationsserver ignoriert und nicht automatisch ausgeführt.
Über die beiden Buttons rechts oben kann das Mapping in eine Datei exportiert werden, um es auf das Kundensystem zu übertragen und dort mit dem zweiten Button wieder zu importieren. Diese Funktion ist ebenfalls nützlich, um vor Änderungen am Mapping ein Backup des Mappings zu erstellen.
Der Hauptteil (untere Teil) des Mappingeditors ist in einen linken und einen rechten Bereich unterteilt.
Standardmäßig dient der linke Teil der Definition des Mappings und der rechte Teil der Ausgabe, allerdings können die Tabs per Drag and Drop beliebig von der einen auf die andere Seite gezogen werden, um zum Beispiel das Tab mit dem Mapping und das Tab mit der Musterdatei gleichzeitig betrachten zu können.
Besonders nützlich ist der auf dem Screenshot zu sehende Tab “Hilfe”, welches in einem separaten Tutorial genauer beschrieben wird.
Auf der linken Seite sind die Tabs Ausführung und Übertragung für alle Mappings relevant.
Zunächst zum Tab Übertragung:
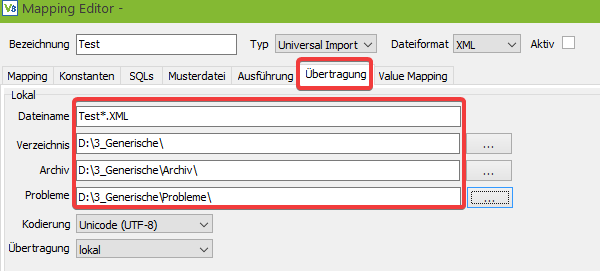
Hier wird definiert, welche Dateien importiert bzw. exportiert werden. Beim Import kann im Feld Dateiname das Zeichen “*” als Platzhalter verwendet werden, z. B. “*.xml”.
Beim Export können Platzhalter für das Datum verwendet werden: z. B. export-YYYY-MM-DD-hh-mm-ss.xml
Das Verzeichnis hat zwei Funktionen: Wenn im unteren Teil eine Datenübertragung per (S)FTP gewählt wird, dann dient es als temporäres Arbeitsverzeichnis. Falls die Dateien nur lokal abgelegt werden, dann wird es als Ein-/Ausgabeverzeichnis verwendet.
Archiv: Das Archivverzeichnis dient wie der Name bereits sagt, der Archivierung von importierten und exportierten Dateien, da diese normalerweise nach der Verarbeitung aus dem Arbeitsverzeichnis entfernt werden.
Fehler: Im Fehlerverzeichnis werden Dateien abgelegt, bei denen etwas schiefgegangen ist.
Wählt man in der Combobox Übertragung ein Protokoll für die Übertragung aus, dann werden im unteren Teil automatisch die passenden Eingabefelder zum Konfigurieren der Übertragung eingeblendet.
Achtung: Bei eingetragenen Übertragungspfaden (z.B. FTP) wird auf diese bei Ausführen des Mappings ggf. zugegriffen bzw. es werden dort Dateien abgelegt.
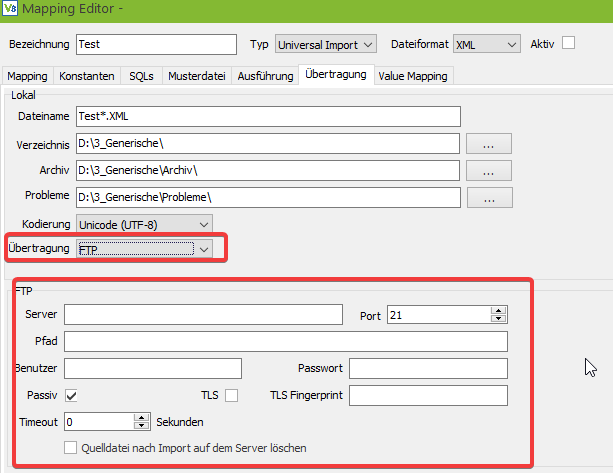
Nachdem die Ausgabe bzw. Übertragung konfiguriert ist, kommen wir zum Tab “Ausführung”.
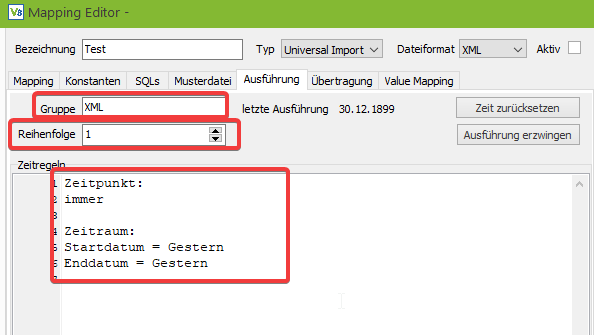
Im großen rot markierten Feld kann durch Zeitregeln definiert werden, wann das Mapping ausgeführt werden soll. Da die Möglichkeiten zur Zeitsteuerung recht umfangreich sind, werden diese in einem eigenen Tutorial genauer erläutert.
Im oberen Teil des Tabs gibt es noch zwei weitere (hier markierte) Felder. Die Gruppe dient dazu mehrere Mappings zu gruppieren. Der Hintergrund ist, dass einige Kunden 60 oder 70 Mappings verwenden, was für einen Replikationsserver eine ziemlich große Last bedeuten würde. Daher können die Mappings in mehrere Gruppen unterteilt werden und mehrere Replikationsserver können jeweils eine Gruppe abarbeiten.
Das zweite Feld “Reihenfolge” bestimmt die Reihenfolge in der die Mappings abgearbeitet werden. Dadurch können Abhängigkeiten berücksichtigt werden. Z. B. das zunächst die Artikel und erst danach die Bestellungen importiert werden.
Die beiden Buttons “Zeit zurücksetzen” und “Ausführung erzwingen” dienen zur Steuerung des Replikationsservers.
Bei einem Mapping, welches nur einmal am Tag ausgeführt werden soll, wird über den Button „Zeit zurücksetzen“ die Markierung, dass das Mapping bereits ausgeführt wird, entfernt und das Mapping wird beim nächsten Durchlauf des Replikationsservers erneut verarbeitet.
Der Button “Ausführung erzwingen” deaktiviert einmalig die Zeitsteuerung, sodass das Mapping beim nächsten Lauf des Replikationsservers, unabhängig von Datum, Wochentag und Uhrzeit, auf jeden Fall ausgeführt wird.
Mehr hierzu weiter unten im Abschnitt “Zeitsteuerung”.
Dies sind die grundlegenden Einstellungen des Mappingeditors, die bei jedem Mapping benötigt werden. Die übrigen Tabs werden im Rahmen weitere Tutorials im jeweiligen Kontext näher erklärt.
Integrierte Hilfefunktion und Tastenkombinationen
Beim Starten des Mappingeditors werden im Tab “Hilfe” automatisch ein paar wichtige Tastenkombinationen angezeigt.
Weitere hilfreiche Tastenkombinationen:
- Textsuche ab Cursor: strg + shift + h
- Einrücken markierter Zeilen durch Tab: strg + shift + i
- Temporäres Lesezeichen für Zeile: strg + shift + Ziffer
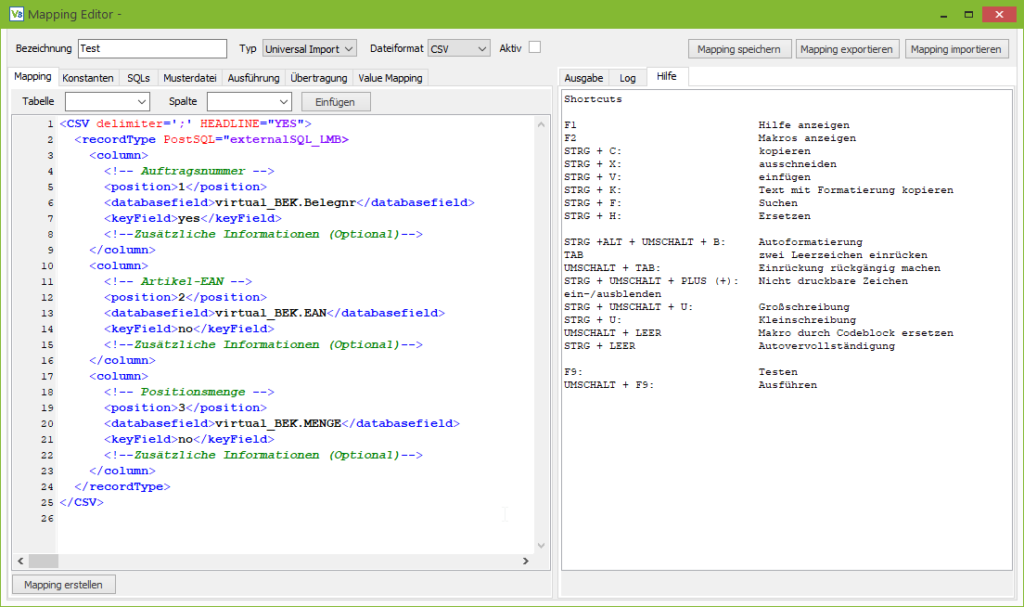
In den Tabs “Mapping”, “Konstanten” und “SQLs” stehen je nach Mappingtyp und Dateiformat Makros und ein Kontextmenü mit passenden Code Elementen zur Verfügung.
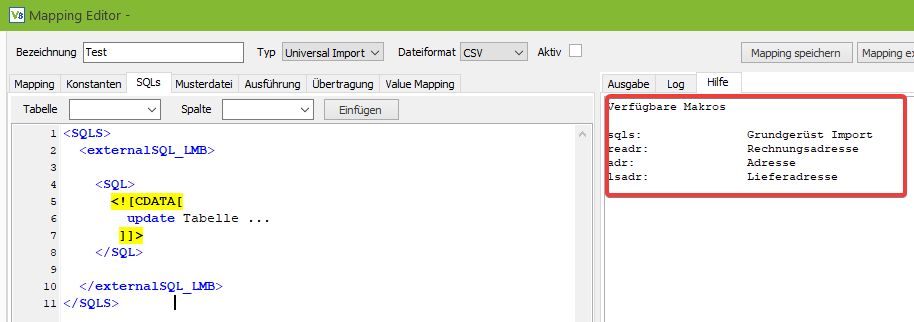
Makros bezeichnen hier Kurzbezeichnungen, die nach dem Eintippen durch Drücken von Umschalt- und Leertaste durch einen größeren Codeblock ersetzt werden.
Z. B. wird das Grundgerüst für die externen SQLs, welches im Screenshot zu sehen ist, durch Eingabe von “sqls” und der genannten Tastenkombination erzeugt.
Die verfügbaren Makros werden angezeigt, wenn man in das entsprechende Editorfenster klickt und F2 drückt.
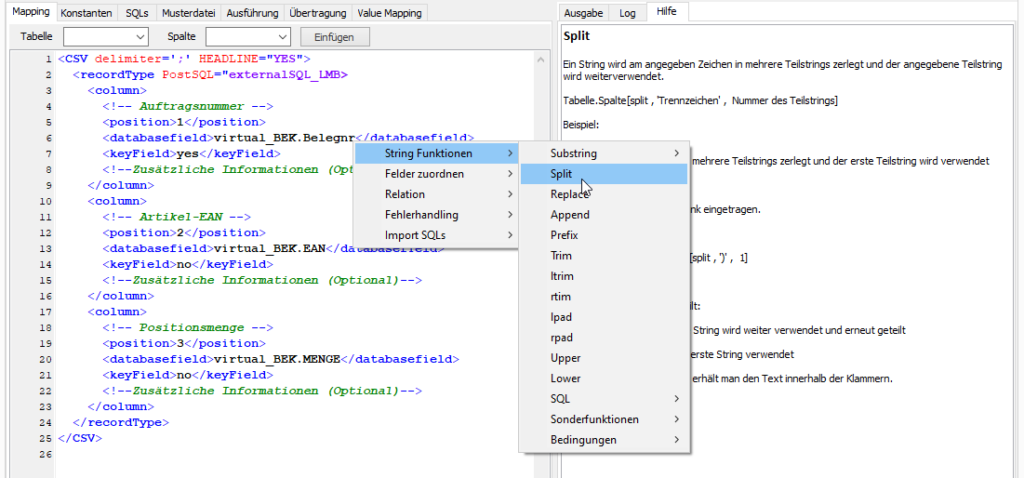
Neben Makros gibt es bei den Importen noch ein mächtiges Kontextmenü (Rechtsklick), welches hier benötigt wird, um z. B. die String-Funktionen zum Bearbeiten der importierten Daten ins Mapping einzufügen.
Drückt man beim Anklicken eines Punktes im Kontextmenü die STRG Taste, dann wird im Tab “Hilfe” eine Erklärung zum angeklickten Befehl angezeigt.
Export-Mappings erstellen
Der Universal Export der Generischen Filiale erlaubt es, beliebige Daten aus der VARIO 8 Datenbank in Dateien der Typen XML, CSV und Excel zu exportieren.
Beim Erstellen des Mappings spielt das gewünschte Dateiformat zunächst keine Rolle für die Vorgehensweise.
Als Grundlage für den Export werden als erstes die SQL-Anweisungen erstellt, mit denen die benötigten Daten zusammengestellt werden. Aus dem Ergebnis der SQL Anfragen wird dann eine Rohfassung des Mappings generiert, welche im weiteren Verlauf Schritt für Schritt an die Spezifikation des Kunden angepasst wird.
Zunächst muss ein neues Mapping angelegt werden, und dazu in der Kopfleiste der Typ als “Universal Export” eingestellt werden. Außerdem ist die Auswahl des gewünschten Dateiformats notwendig.
Wie bereits erwähnt, werden zunächst die SQL-Anweisungen definiert, dazu muss der Tab SQLs geöffnet werden. Als Arbeitserleichterung stehen in den Tabs “Mapping”, “Konstanten” und “SQLs” Makros zur Verfügung, mit denen Codeblöcke erzeugt werden können.
Die verfügbaren Makros werden angezeigt, wenn man in das entsprechende Editorfeld klickt und F2 drückt.
Auf dem Screenshot unten sehen wir, dass der Makrobefehl “sqls” ein Grundgerüst für den Export erzeugt, daher geben wir im Editor “sqls” ein und drücken anschließend gleichzeitig die UMSCHALT- und die LEERTASTE. Durch die Tastenkombination wird aus dem “sqls” der Codeblock, der auf dem nächsten Screenshot zu sehen ist:
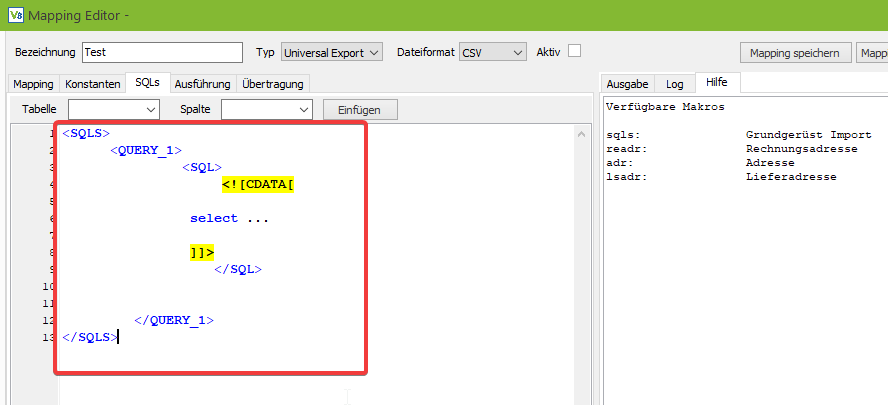
Analog können mit “query” weitere Queries für 1:n Relationen erstellt werden usw.
Die SQL für einen Belegexport könnten folgendermaßen aussehen:
<SQLS>
<QUERY_BEK>
<SQL>
<![CDATA[
select
BEK.ID
, BEK.BELEGNR
, BEK.BELEGDATUM
, BEK.NAME1
, BEK.NAME2
, BEK.RE_NAME1
, BEK.RE_NAME2
, BEK.LS_NAME1
, BEK.LS_NAME2
from bek
where bek.adressnr = :adressnr
and bek.belegtyp in ('03')
and bek.belegstatus >= '3'
and not exists ( select bek_mov.id
from bek_mov
where bek_mov.bek_id = bek.id
and bek_mov.repliziert_jn='J')
order by bek.belegschluessel
]]>
</SQL>
<QUERY_BEP>
<SQL>
<![CDATA[
select
BEP.ARTIKELNR
, BEP.MENGE
, BEP.EINZELPREIS
from bep
where bep.bek_id = :QUERY_BEK.ID
]]>
</SQL>
</QUERY_BEP>
<SUCCESSSQL_BEK>
<SQL>
<![CDATA[
insert into BEK_MOV (bek_id, repliziert_jn) values ( :QUERY_BEK.ID, 'J')
]]>
</SQL>
</SUCCESSSQL_BEK>
</QUERY_BEK></SQLS>
Hinweis: In diesem Tutorial geht es darum, die grundlegende Vorgehensweise bei Erstellen eines Exportmappings an einem möglichst einfachen und übersichtlichen Beispiel zu erklären. Aus diesem Grund ist das Mapping auf ein paar Felder zusammen gestutzt und es handelt sich nicht um ein Referenzmapping, das in einem Kundenprojekt verwendet werden sollte.
Besonders auffällig an dem Beispiel ist, dass es sich um eine Mischung aus XML und SQL handelt. Das XML Gerüst dient dazu die SQLs zu strukturieren.
Der Knoten <SQLS> (und das dazugehörende </SQLS>) ist der Wurzelknoten, der den Anfang und das Ende der XML Datei markiert. Dazwischen können wir beliebig viele QUERY_, SUCCESSSQL_ und ERRORSQL_ Knoten erzeugen.
Die QUERY_ Knoten definieren die SQL Anfragen, die uns die Daten für den Export liefern, also ein Select oder einen Execute Block mit Rückgabewerten.
Innerhalb des QUERY_ Knotens können mehrere SQL Knoten stehen, die den auszuführenden SQL Code enthalten, aber auch weitere QUERY_ Knoten und auch SUCCESSSQL_ und ERRORSQL_ Knoten, die nach einem erfolgreichen bzw. fehlgeschlagenen Export ausgeführt werden.
Da SQL-Code Sonderzeichen enthält, welche auch von XML verwendet werden muss der SQL Code zwischen den Markierungen <![CDATA[ und ]]> stehen. Dadurch erkennt der XML Parser, dass es sich um Zeichen handelt, die nicht analysiert bzw. nicht als XML-Code gelesen werden sollen.
Im Beispiel wird zunächst die QUERY_BEK definiert, die die Belegköpfe ermittelt. Auf die verwendeten Filter dieser Anfrage gehen wir weiter unten ein.
Zu jedem Belegkopf benötigen wir auch die Belegpositionen, die uns die QUERY_BEP liefert. Dadurch, dass der Knoten QUERY_BEP innerhalb des Knotens QUERY_BEK definiert wird, weiß der Mappingeditor, dass es sich um eine Unterabfrage bzw. 1:n Relation handelt und erzeugt später das Mapping entsprechend.
Interessant ist dabei Folgendes:
where bep.bek_id = :QUERY_BEK.ID
Über :QUERY_NAME.FELDNAME können wir die Werte der übergeordneten QUERY als Parameter im SQL verwenden und damit die Verknüpfung für die 1:n Relation herstellen.
Ein Hinweis an dieser Stelle: Wird statt eines Selects ein Execute Block verwendet, dann funktioniert die Übergabe der Werte nur bei den Parametern des Execute Blocks:
EXECUTE BLOCK (BEK_ID Integer = :QUERY_BEK.ID)
Innerhalb des Execute Blocks kann dann mit :BEK_ID gearbeitet werden, aber :QUERY_BEK.ID ist dort nicht verfügbar.
Neben den beiden QUERY_ Knoten gibt es in dem Beispiel noch den Knoten SUCCESSSQL_BEK
Die SUCESSSQL_ Knoten sind an eine QUERY gebunden und werden nach jedem erfolgreich exportierten Datensatz ausgeführt. Analog dazu gibt es auch ERRORSQL_ Knoten für den Fehlerfall.
Der Knoten SUCCESSSQL_BEK dient dazu, den jeweiligen Beleg als exportiert zu markieren, in dem in der Tabelle BEK_MOV ein Eintrag erzeugt wird. Über :QUERY_BEK.ID wird wieder die Verknüpfung zum aktuellen Belegkopf hergestellt.
Durch das SuccessSQL erklärt sich auch die “exists”-Bedingung in der QUERY_BEK, da nur die Belege exportiert werden sollen, die noch nicht in der BEK_MOV markiert wurden.
Des Weiteren existiert in der QUERY_BEK noch der Parameter :adressnr, der uns zum nächsten Tab bringt.
Die SQL-Anweisungen sind häufig recht aufwendig, jedoch in vielen Fällen ähnlich. Bei Belegen werden fast immer dieselben Felder benötigt und bei Preislisten sind die Ähnlichkeiten noch größer.
Um die SQL-Anweisungen leichter wieder verwenden zu können, ohne an zahlreichen Stellen die Adress- oder Kundennummer ändern zu müssen, ist es möglich diese als Parameter im Tab Konstanten zu definieren.

In einem späteren Tutorial gehen wir dann noch darauf ein, wie man die SQL-Anweisungen zentral in einem Master Mapping pflegt und in den Ableitungen nur die Parameter anpasst.
Die Definition der Parameter im Tab “Konstanten” ist recht simpel. Per Makro params und UMSCHALT + LEER wird das Grundgerüst erzeugt und dann so viele “param”-Knoten definiert wie nötig. Links vom Gleichzeichen steht der Name des Parameters ohne den Doppelpunkt, also in diesem Fall ADRESSNR und rechts der Wert z. B. 100011.
Neben den selbst definierten Parametern stellt der Export auch die Parameter: vonDatum und bisDatum bereit, die einen Zeitraum der Daten festlegen und im Tutorial zum Zeitmapping genauer erklärt werden.
Nachdem die Parameter und die SQLs definiert wurden kann jetzt im Tab SQLs über den Button unten links das eigentliche Mapping generiert werden.
Ab diesem Zeitpunkt kommen die Unterschiede zwischen den Dateiformaten zum Tragen.
XML Export
Beim XML Export entspricht das Mapping weitestgehend der Datei, die erzeugt werden soll. Anstelle der Werte werden Platzhalter in der Form Query_name.Feld eingesetzt und die Knoten, die mehrfach erzeugt werden sollen bekommen als Attribut eine Query zugewiesen.
Der Screenshot zeigt die Unterschiede zwischen Mapping und der erzeugten Datei:
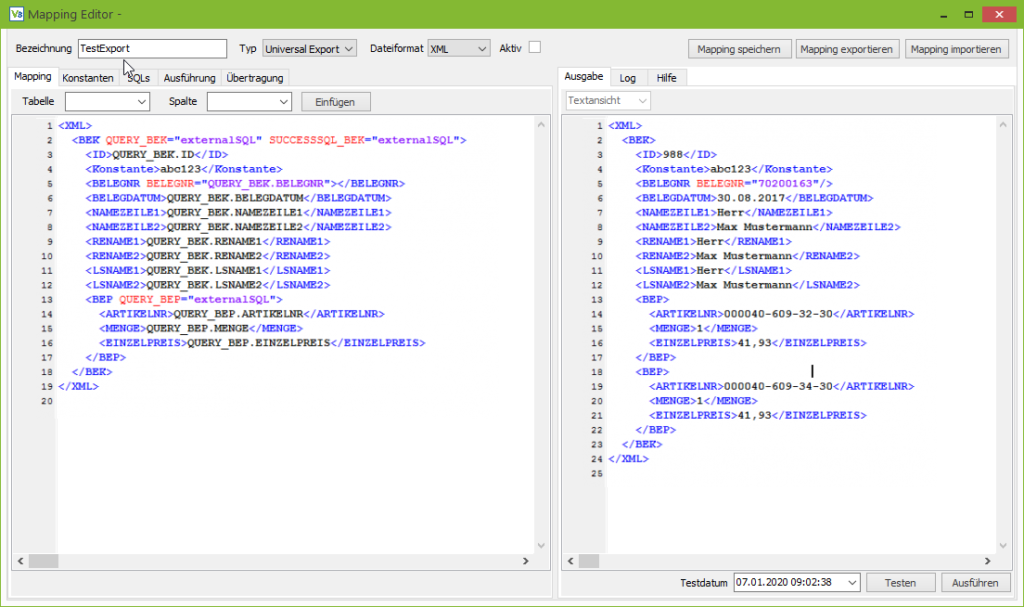
Im Mapping auf der linken Seite enthält der Knoten BEK das Attribut QUERY_BEK, daher wird für jeden Datensatz, den die Query liefert, ein BEK Knoten erzeugt.
Das Attribut SUCCESSSQL_BEK weist der Anfrage den SQL-Code zu, der für jeden erfolgreichen Datensatz ausgeführt wird.
Der Wert ExternalSQL verweist darauf, dass der SQL-Code im separaten Tab “SQLs” definiert wurde und nicht (, wie es bei Mappings älterer Versionen der Fall war,) innerhalb des Mappings.
Der exportierte Beleg besitzt zwei Positionen, daher wurde der Knoten BEP zweimal erzeugt.
Im Beispiel-Mapping gibt es zwei Besonderheiten:
Zum einen den Knoten Konstante, der zeigt, dass Texte die keinem Query-Feld oder Parameternamen entsprechen, als Konstanten in die erzeugte Datei übernommen werden.
Ein eher seltener Fall ist die Verwendung von XML Attributen, wie es bei der Belegnummer zu sehen ist, was allerdings nicht weiter stört, da hier genau wie bei normalen XML-Knoten einfach der Feldname bzw. die Konstante eingetragen wird.
Abschließend lässt sich zum XML-.Export sagen, dass es zwei mögliche Vorgehensweisen gibt:
Entweder nimmt man eine Beispieldatei vom Kunden und ersetzt die Musterdaten durch die Platzhalter oder man erzeugt ein Basismapping und passt dieses Schritt für Schritt an die Vorgaben des Kunden an. Wie man hier vorgeht, ist Geschmackssache.
CSV/Excel Export
Da die Mappings für die Formate Excel und CSV bis auf ein Detail identisch sind, macht eine Unterscheidung an dieser Stelle keinen Sinn. Aus Gründen der Lesbarkeit wird im weiteren Verlauf nur noch CSV genannt, aber die Zusammenhänge gelten 1:1 auch für Excel.
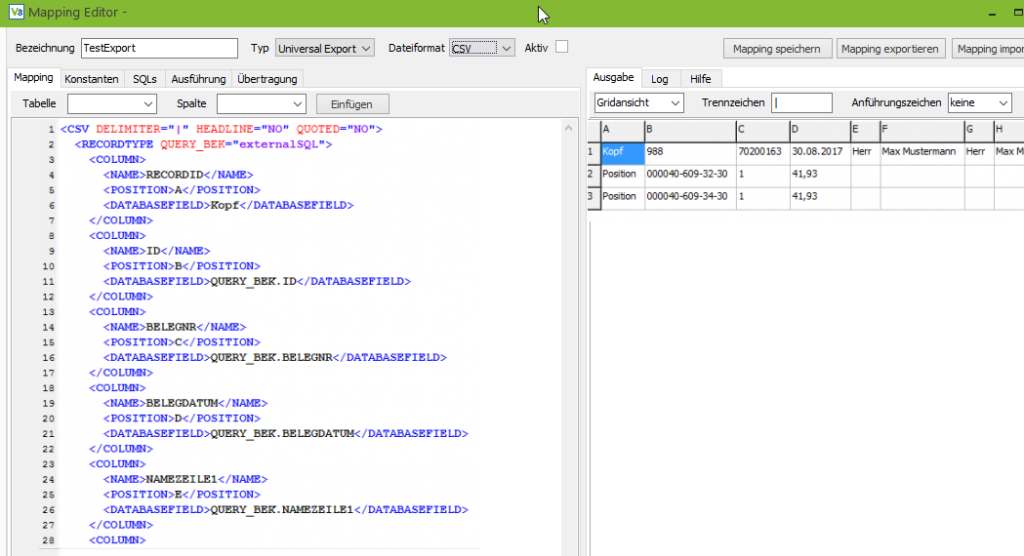
Grundsätzlich wird das Mapping für CSV-Dateien in Form einer XML-Datei beschrieben.
Dabei gibt es 3 Hauptelemente:
Im Wurzelknoten CSV werden einige Grundeinstellungen für die komplette Datei festgelegt. Das Attribut Delimiter definiert das Trennzeichen, dass in der CSV Datei verwendet wird. Da Exceldateien kein Trennzeichen haben, ist das Attribut dort nutzlos und kann weggelassen werden. Hierin unterscheiden sich die beiden Formate.
Headline definiert, ob eine Zeile mit Überschriften ausgegeben werden soll.
Quoted legt fest, ob die Werte in Anführungszeichen gesetzt werden. Mögliche Werte sind NO, SINGLE und DOUBLE für keine, einfache bzw. doppelte Anführungszeichen.
Die Recordtype Knoten sind das zweite wichtige Element über das verschiedene Datensatztypen definiert werden können, um z. B. in eine Zeile mit dem Belegkopf gefolgt von N-Zeilen mit den dazugehörenden Positionen, danach dann der Kopf vom nächsten Beleg usw. auszugeben.
Eine 1:N Relation zwischen zwei Datensatztypen (wie dem Belegkopf und seinen Positionen) definiert man, in dem man die Recordtype Knoten in einander schachtelt.
Das dritte Element sind die Column Knoten über die die Spalten definiert werden.
Entscheidend sind hier zum einem der Knoten POSITION, der die Spaltennummer festlegt. Es können dabei sowohl Zahlen (1, 2, 3, …) verwendet werden, als auch die Excel Spaltennummerierung (A, B, C, …, Z, AA, AB, …). Da CSV-Musterdateien häufig mit Excel geöffnet werden und oft viele leere Spalten enthalten, hat sich die Excel Nummerierung bewährt.
Wichtig ist dabei, dass bei Export ausschließlich die Position als Kriterium für die Reihenfolge der Spalten verwendet wird. Die Reihenfolge der Column-Knoten im Mapping kann frei gewählt werden und ausgelassene Spaltennummern werden automatisch durch leere Spalten aufgefüllt. Bei mehreren leeren Spalten am Ende muss lediglich die letzte Spalte definiert werden, damit der Export erkennt, wie viele leere Spalten er ausfüllen muss.
Der Knoten Databasefield gibt an, was in die Datei geschrieben werden soll. Hier können entweder Verweise auf die Queries stehen oder Konstanten.
Der Knoten “Name” ist optional und dient dazu, Überschriften für die Spalten zu definieren, falls in der Wurzel Headline auf YES gesetzt wurde. Die Überschrift macht nur in Fällen Sinn, in denen lediglich ein Datensatztyp definiert wurde.
Testen
Nachdem das Mapping erstellt wurde, beginnt die Testphase. Um mit den Tests beginnen zu können, müssen im Tab “Übertragung” die Verzeichnisse gesetzt werden, da bei einigen Tests im Hintergrund temporäre Dateien erstellt werden.
Die Testfunktionen sind im rechten Teil des Editors im den Tabs Ausgabe und Log zu finden. Der Tab Ausgabe dient dazu, die generierten Dateien anzuzeigen. Bei XML-Dateien wird die Datei angezeigt und bei CSV- und Excel-Dateien kann zwischen Text- und Grid-Ansicht umgeschaltet werden.
Im Tab Log werden die Meldungen des Exports ausgegeben, so z. B. Hinweise zu fehlerhaften SQL-Anweisungen.
Unten rechts sind bei beiden Tabs die zwei Buttons “Testen” und “Ausführen” zu finden.
Der Button Testen gibt im Ausgabe-Tab den Inhalt der zu erzeugenden Datei aus. Im Test-Modus werden weder die Success- und ErrorSQLs ausgeführt, noch Dateien erzeugt.
Der zweite Button Ausführen führt das komplette Mapping exakt so aus, wie es der Replikationsserver tun würde, inklusive Zeitprüfung, aller Success- und Error-SQLs, dem Erzeugen und gegebenenfalls auch Übertragen der Datei auf den (S)FTP Server. Die Funktion kann zum manuellen Ausführen von Mappings genutzt werden, allerdings ist der Hauptzweck des Erstellens von Mappings den ständigen Wechsel zwischen Mappingeditor und Replikationsserver zu vermeiden.
Die Auswahlbox für das Testdatum dient zum Testen der Zeitsteuerung und zur Prüfung, ob der Zeitraum der exportierten Daten stimmt. Näheres dazu ist im Tutorial zur Zeitsteuerung zu finden.
Import-Mappings erstellen
Die Generische Filiale bietet verschiedene Importe wie den Universal Import, den BEK, BSK und ART Import an. Technisch basieren alle auf dem Universal-Import und unterscheiden sich lediglich dadurch, dass einige Konstanten automatisch gesetzt werden, um die Arbeit beim Erstellen des Mappings zu erleichtern, daher wird in den Tutorials nur zwischen den Dateiformaten unterschieden, die unterschiedliche Mappings benötigen.
Da sowohl CSV- als Excel-Dateien die Daten in Tabellenform speichern, werden beide Formate von der Generischen Filiale gleich behandelt. Der einzige Unterschied ist die Definition des Trennzeichens, die bei Exceldateien überflüssig ist. Daher können die Informationen aus diesem Tutorial 1:1 für Exceldateien angewendet werden, auch wenn im weiteren Verlauf der Einfachheit halber nur noch CSV erwähnt wird.
Import von CSV/Excel-Dateien
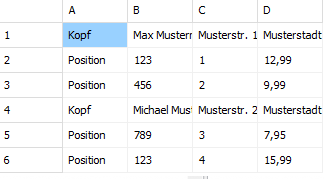
Grundsätzlich gibt es bei Tabellen zwei Möglichkeiten Daten einer 1:n Relation zu speichern
Bei der ersten Variante werden verschiedene Datensatztypen definiert, die am Anfang entsprechend gekennzeichnet sind.
{kind=link}
Im Beispiel folgen auf einen Belegkopf die dazugehörenden Positionen und danach geht es mit dem nächsten Beleg weiter.
Die zweite Variante entspricht einem SQL Join der Tabellen
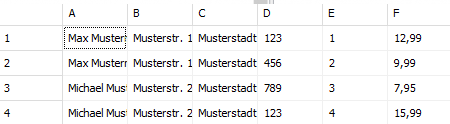
In dem Beispiel werden die ersten Spalten mit den Daten des Belegkopfs bei jeder Position wiederholt.
Die Generische Filiale kann beide Varianten verarbeiten, allerdings müssen im Mapping ein paar Besonderheiten beachtet werden, damit die Daten korrekt verarbeitet werden können.
Variante 1: CSV mit mehreren Datensätzen
Dazu gehen wir in den Tab Mapping und klicken auf Mapping erstellen.
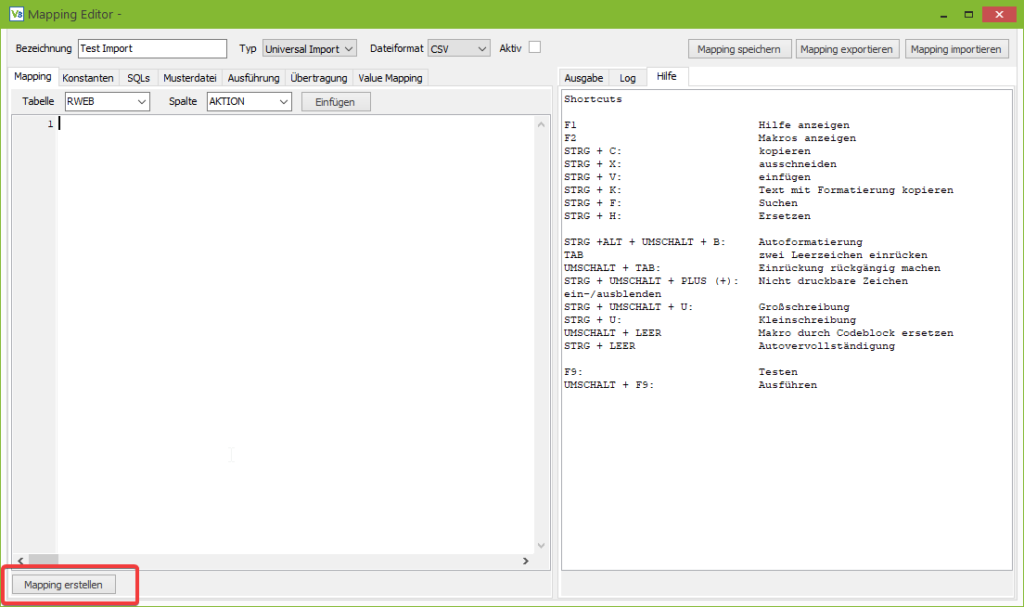
Der Assistent generiert ein Grundgerüst für das Mapping.
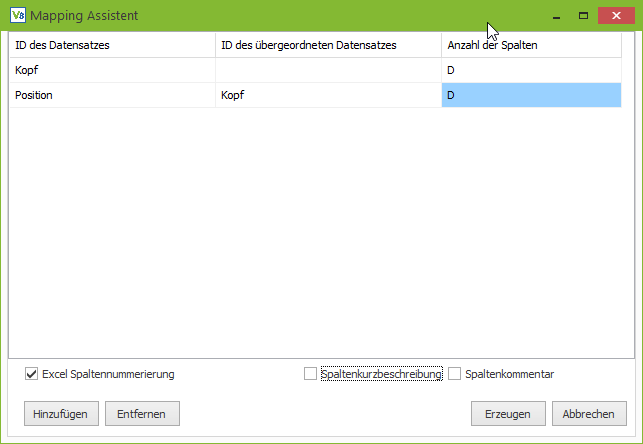
Da CSV-Dateien wegen der besseren Lesbarkeit gerne mit Excel geöffnet werden, kann die Buchstaben Spaltennummerierung von Excel auch in der Generischen Filiale verwendet werden. Bei der Anzahl der Spalten wird dann einfach der Buchstabe der letzten Spalte eingetragen anstatt nachzuzählen, dass BY Spalte 77 ist.
(Das normale Öffnen von CSV-Dateien in Excel mit anschließendem Speichern ist nicht zu empfehlen. Um CSV-Daten in Excel zu laden, kann aus dem Reiter “Daten” der Punkt “Aus Text/CSV” ausgewählt werden und dieser Inhalt dann separat gespeichert werden.)
Über die Checkbox “Excel Spaltennummerierung” kann festgelegt werden, ob die Spalten im Mapping numerisch oder im Excel-Stil durchnummeriert werden. Beide Varianten können auch beliebig gemischt werden.
In der Tabelle werden die Kennungen der Datensätze und die jeweilige Anzahl der Spalten eintragen.
Danach wird mit dem Button Erzeugen das Mapping Gerüst generiert.
Für jeden Datensatztyp wird ein RecordType-Knoten angelegt, der pro Spalte einen Column-Knoten enthält.
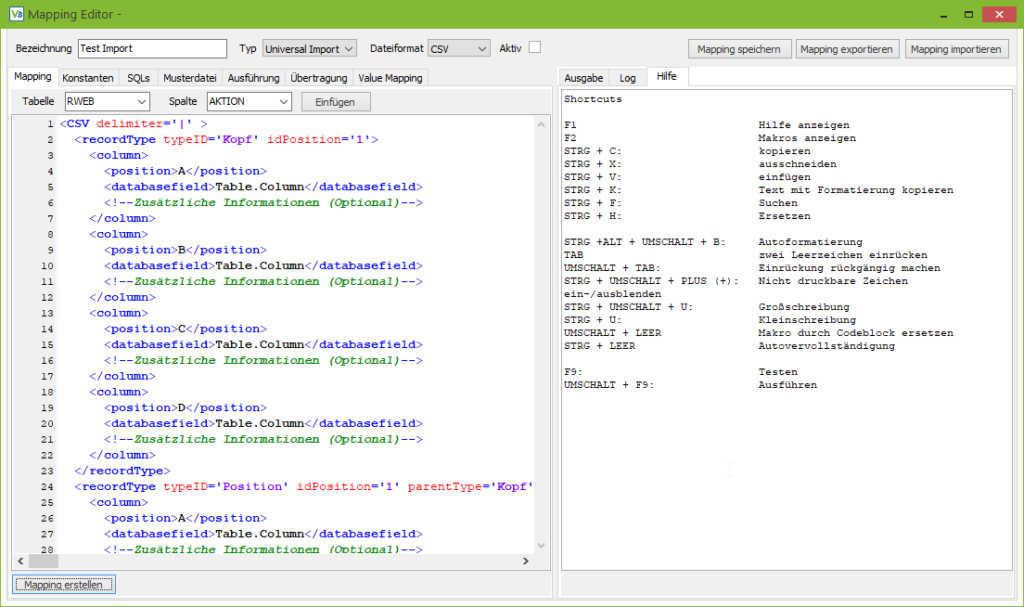
Als Erklärung dazu ein paar technische Hintergrundinformationen:
Der CSV-Import speichert die Datei zunächst in einer Baumstruktur zwischen. Dabei wird für jeden Beleg ein Knoten angelegt, der dann wiederum die dazugehörenden Positionen als Unterknoten enthält. Nachdem der Baum eingelesen wurde, werden die Daten dann Daten aus den Belegknoten in die Tabelle RWEB_BEK und die Positionen in die RWEB_BEP (Tabellen für den Webshopimport) geschrieben.
Durch die Baumstruktur ist es möglich, Referenzen zwischen beiden Tabellen herzustellen.
Die RecordType-Knoten haben einige weitere Besonderheiten. Um in der Datenbank die Positionen mit dem Belegkopf zu verknüpfen, muss in der RWEB_BEP.BEK_ID die ID des RWEB_BEK-Datensatzes eingetragen werden.
Dies wird dem Import über das Attribut REFERENCE=”RWEB_BEP.BEK_ID = RWEB_BEK.ID” mitgeteilt. Da der Import intern mit einem update or insert arbeitet, muss ein Matching festgelegt werden. So kann der Import feststellen, ob es ein neuer oder ein aktualisierter Datensatz ist. Dies passiert über: MATCHING=”RWEB_BEK.(EXT_REFERENZ).
Bei den Spezialimporten wie dem BEK-Import entfallen das Matching und die Referenzen, da sie automatisch gesetzt werden. Notwendig sind sie lediglich beim Universal Import.
Es können auch SQL-Anweisungen für die Verarbeitung der Daten und zur Fehlerbehandlung in den RecordType-Knoten definiert werden, aber dies wird in separaten Tutorials näher erläutert.
Variante 2: CSV-Dateien mit Join
Bei Tabellen die wie ein Join aufgebaut sind, ist die Vorgehensweise zum Generieren des Grundgerüsts ähnlich.
Zunächst rufen wir den Assistenten zum Generieren des Grundgerüsts auf.
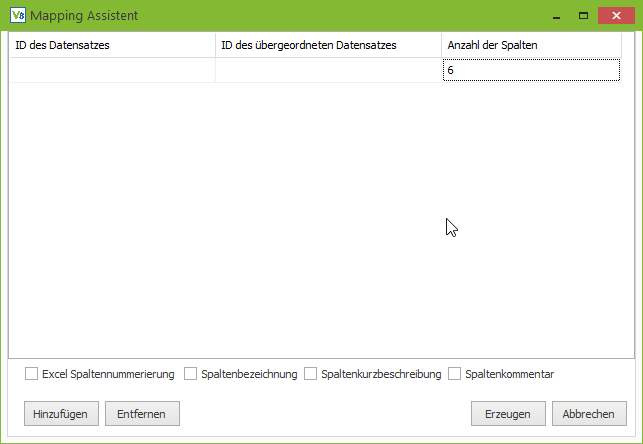
Diesmal wird nur ein Datensatz definiert und die ID des Datensatzes leer gelassen.
In dem erzeugten Mapping müssen jetzt noch von Hand die Spalten, die zur Belegposition gehören mit einem <subtable> </subtable> umschlossen werden.
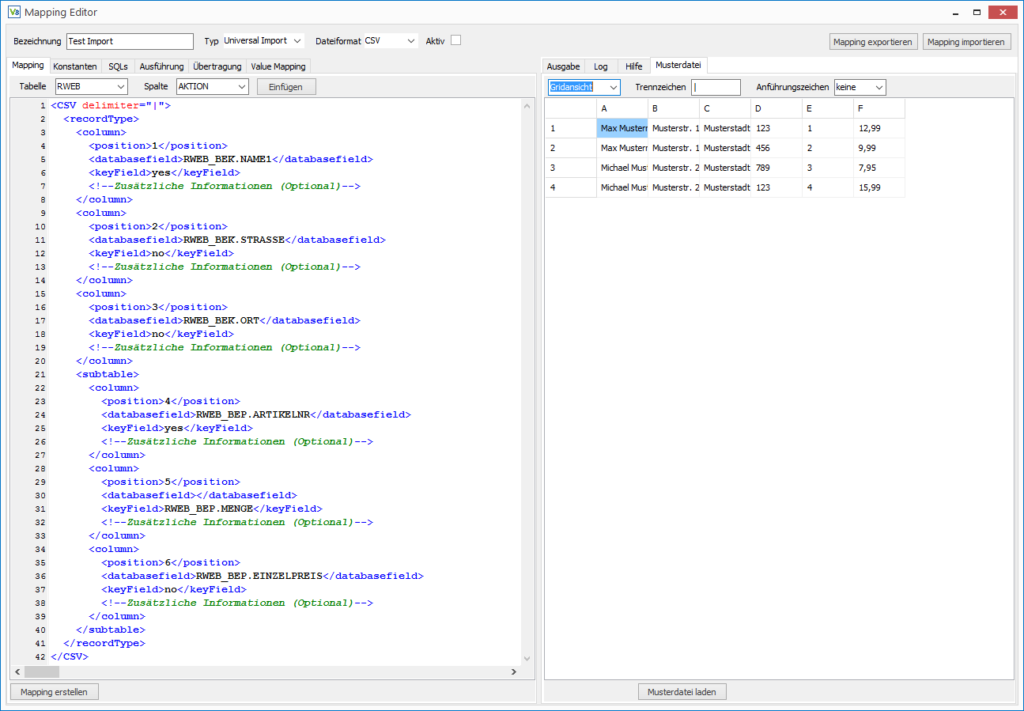
Im Subtable Knoten müssen dann analog zum RecordType das Matching und die Referenzen eingetragen werden.
Um zu erkennen, ob es sich bei einer Zeile um die nächste Position des aktuellen Belegs oder um die erste Position eines neuen Belegs handelt, müssen einige Spalten als KeyField markiert werden. Am besten eignen sich dafür die Belegnummer und die Positionsnummer. Wenn sich das Keyfield ändert, wird ein neuer Beleg erkannt oder nicht erkannt. Aus technischen Gründen muss auch bei den Positionen ein Keyfield markiert werden.
Zuordnung der Daten
Nachdem das Grundgerüst erstellt wurde und auch die Relationen definiert sind, müssen nur noch die Spalten zu den Datenbankfeldern zugeordnet werden.
Die Column Knoten enthalten zwei wichtige Knoten: position definiert die Spaltennummer in der Datei. Die Reihenfolge der Column Knoten spielt keine Rolle und nicht genutzte Spalten können weggelassen werden.
Im Databasefield wird das Datenbankfeld eingetragen, in das die Daten geschrieben werden sollen.
Wenn alle Felder zugeordnet sind folgt der Test des Mappings. Dazu wird im Tab Ausgabe der Button Testen geklickt.
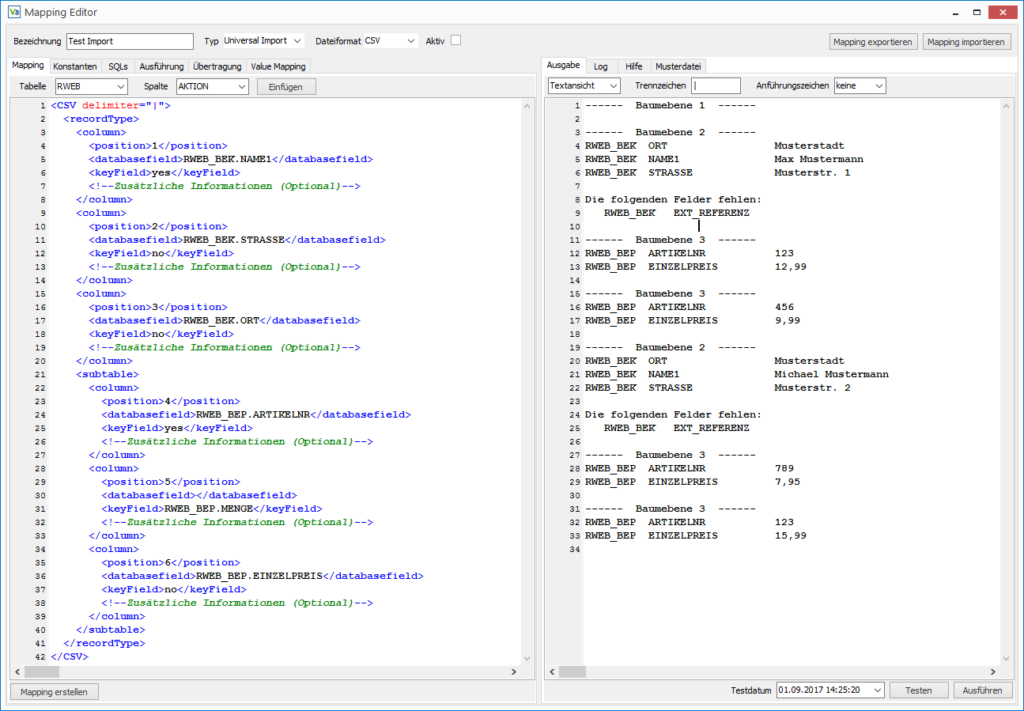
Auf dem Screenshot ist das Ergebnis der Testfunktion zu sehen. Wie bereits erwähnt, werden die Daten in einer Baumstruktur zwischengespeichert. Beim Testen wird diese Baumstruktur ausgeben, ohne dass Änderungen an der Datenbank vorgenommen werden. Dadurch sieht man, was der Import in die Datenbank schreiben würde und kann die Daten entsprechend aufarbeiten.
Fehlermeldungen sind in Tab “Log” zu finden.
Import von XML-Dateien
Die Mappings zum Importieren von XML Dateien entsprechen weitestgehend den XML-Dateien, die importiert werden sollen, daher verfügt der Mapping Editor über Funktion, um aus einer Musterdatei vom Kunden das Grundgerüst für das Mapping zu generieren.
Dazu gehen wir in den Tab Musterdatei und laden die Beispieldatei bzw. kopieren den Inhalt in das Editorfenster.
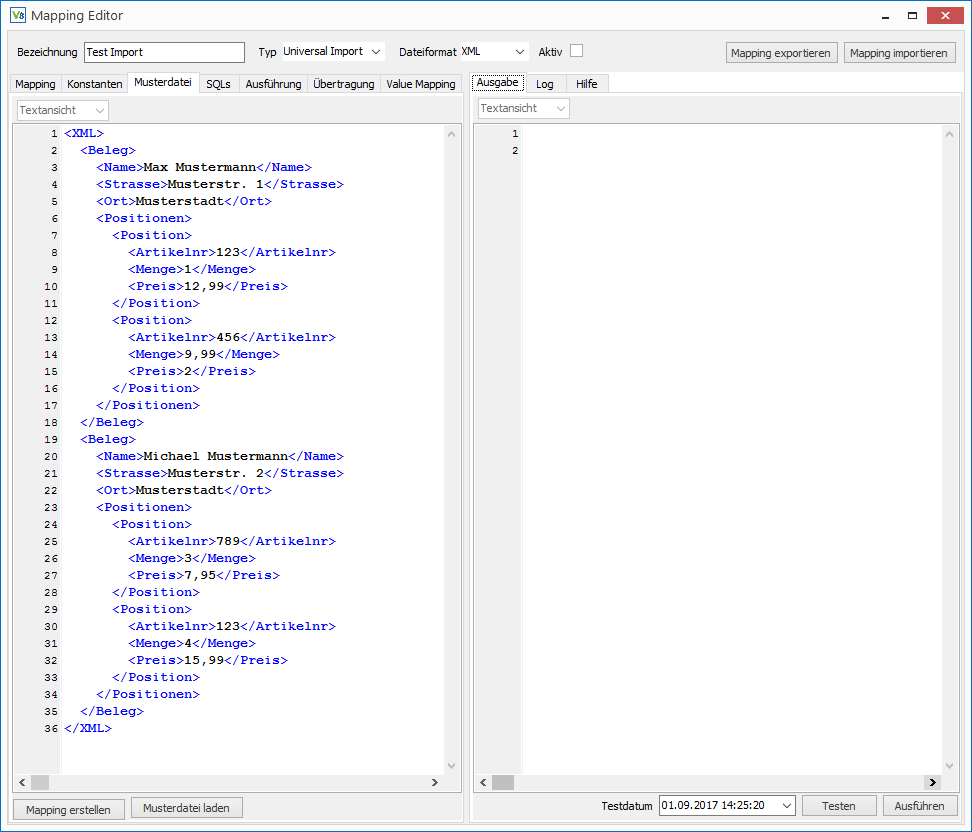
Nach einem Klick auf Mapping erstellen ist im Tab Mapping das Grundgerüst für das Mapping zu finden.
Auf dem folgenden Screenshot wurde das Tab Musterdatei auf die rechte Seite verschoben, um einen direkten Vergleich zwischen Datei und Mapping zu ermöglichen. Die Tabs lassen sich dazu einfach per Drag and Drop nach Bedarf verschieben.
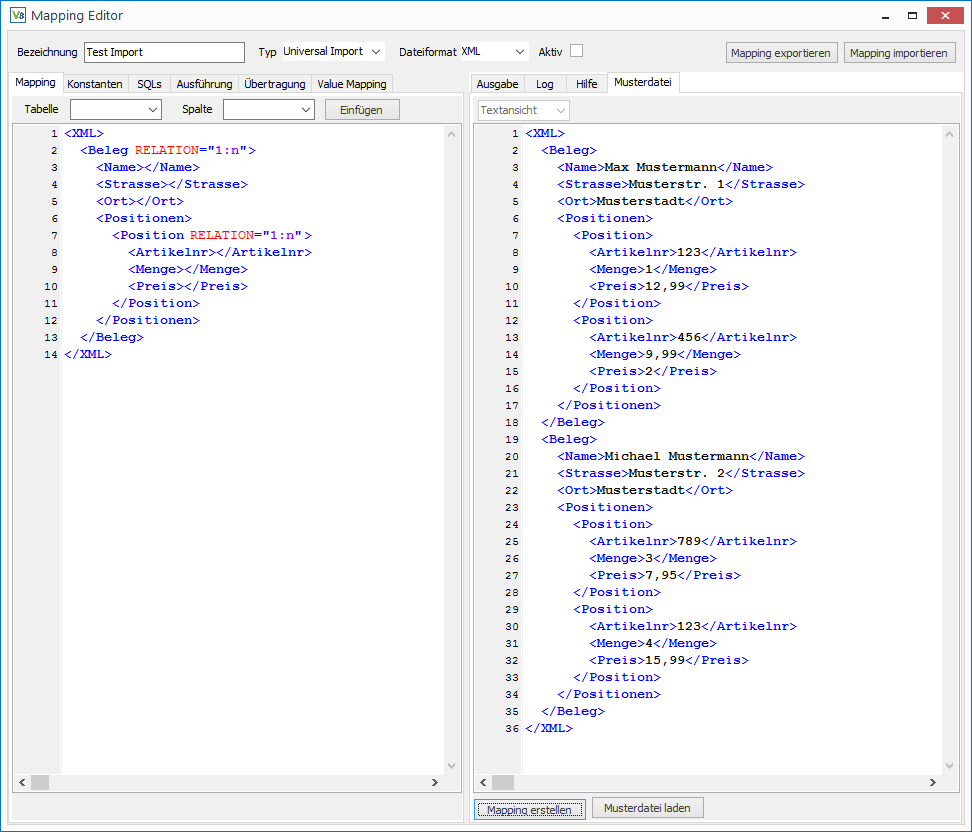
Die Beispieldatei enthält zwei Belege mit jeweils zwei Positionen. Es ist für das Generieren des Grundgerüsts entscheidend, dass alle Knoten die mehrfach vorkommen können auch mindestens zweimal vorkommen, damit der Generator die 1:n Relationen erkennen kann.
In das Mapping wurde jeweils nur eine Kopie der Knoten übernommen, die mehrfach vorkommen und diese wurden mit dem Attribut Relation=”1:n” gekennzeichnet.
Als Erklärung dazu ein paar technische Hintergrundinformationen:
Der XML-Import speichert die Datei zunächst in einer Baumstruktur zwischen. Dabei wird für jeden Beleg ein Knoten angelegt, der dann wiederum die dazugehörenden Positionen als Unterknoten enthält. Nachdem der Baum eingelesen wurde, werden die Daten aus den Belegknoten in die Tabelle RWEB_BEK und die Positionen in die RWEB_BEP geschrieben.
Durch die Baumstruktur ist es möglich, Referenzen zwischen beiden Tabellen herzustellen.
Die Relation=”1:n”-Markierung im Mapping dient dazu dem Parser mitzuteilen, an welcher Stelle er den Baum verzweigen muss.
Die Relation-Knoten haben noch einige weitere Besonderheiten. Um in der Datenbank die Positionen mit dem Belegkopf zu verknüpfen, muss in der RWEB_BEP.BEK_ID die ID des RWEB_BEK Datensatzes eingetragen werden.
Dies wird dem Import über das Attribut REFERENCE="RWEB_BEP.BEK_ID =RWEB_BEK.ID" mitgeteilt. Da der Import intern mit einem update or insert arbeitet, muss ebenfalls ein Matching festgelegt werden, damit der Import feststellen kann, ob es sich um einen neuen oder einen aktualisierten Datensatz handelt. Dies passiert über MATCHING="RWEB_BEK.(EXT_REFERENZ).
Bei den Spezialimporten wie dem BEK-Import entfallen das Matching und die Referenzen, da sie automatisch gesetzt werden. Notwendig sind sie lediglich beim Universal-Import.
Es können auch SQL-Anweisugen für die Verarbeitung der Daten und zur Fehlerbehandlung in der Relation Knoten definiert werden.
Nachdem das Grundgerüst und die Relationen definiert wurden geht es mit der Zuordnung der Felder weiter. Im Prinzip wird einfach in die jeweiligen XML-Knoten eingetragen, in welche Felder die Daten geschrieben werden.
z.B. <Menge>RWEB_BEP.MENGE</Menge>
Die Generische Filiale bietet umfangreiche Möglichkeiten die eingelesenen Daten aufzubereiten, da aber diese Funktionen beim XML- und CSV-Import identisch sind, werden sie in einem separaten Tutorial behandelt anstatt in beiden Import-Tutorials darauf einzugehen.
Wenn alle Felder zugeordnet sind, folgt der Test des Mappings. Dazu wird im Tab Ausgabe der Button Testen geklickt.
Auf dem Screenshot ist das Ergebnis der Testfunktion zu sehen. Wie bereits erwähnt, werden die Daten in einer Baumstruktur zwischengespeichert. Beim Testen wird diese Baumstruktur ausgeben, ohne dass Änderungen an der Datenbank vorgenommen werden. Dadurch sieht man, was der Import in die Datenbank schreiben würde und kann die Daten entsprechend aufarbeiten.
Fehlermeldungen sind in Tab Log zu finden.
Aufbereiten von zu importierenden Daten
Die Daten, die importiert werden müssen, liegen oft in einer ungeeigneten Formatierung vor, daher bietet der Import der Generischen Filiale einen umfangreichen Werkzeugkasten zur Aufbereitung der Daten an.
Der Mappingeditor verfügt im Importmodus über ein Kontextmenü, welches alle zur Verfügung stehenden Funktionen auflistet. Über den normalen Linksklick wird ein entsprechender Mustercode ins Mapping eingefügt. Hält man beim Linksklick die STRG-Taste gedrückt, dann wird im Tab Hilfe eine detaillierte Beschreibung des Befehls angezeigt.
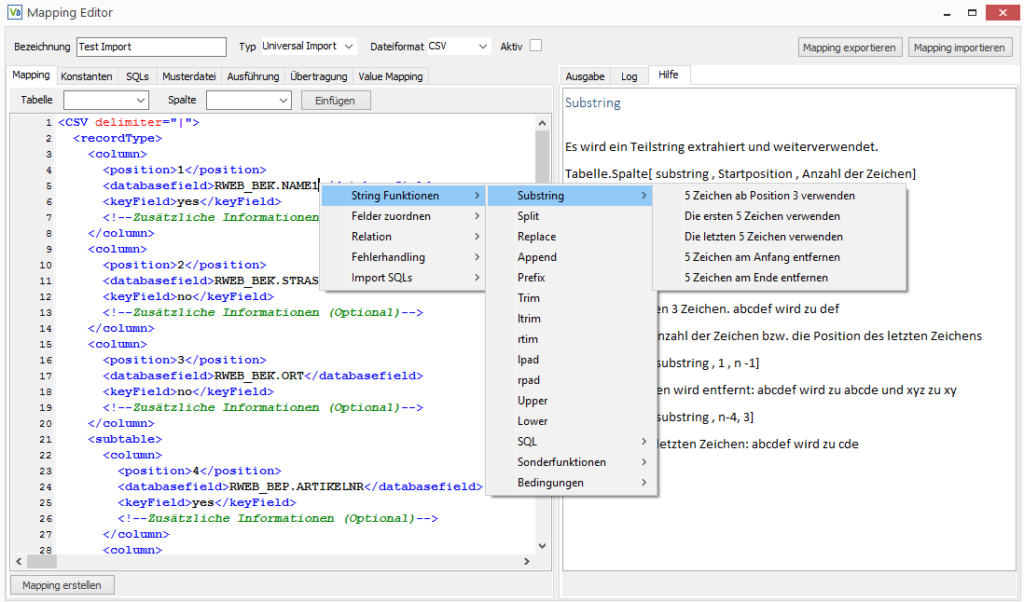
Auf Grund des Umfangs des Themas und der Tatsache, dass die Hilfe des Mappingeditors stets auf dem neusten Stand gehalten wird, dient dieses Tutorial nur als grober Überblick über die häufigsten Fälle, um ein erstes Gefühl dafür zu bekommen, was mit der Generischen Filiale möglich ist und den grundlegenden Umgang mit den Funktionen zu lernen.
Felder mehrfach verwenden
Es gibt einige Informationen, die in mehreren Datenbankfeldern, bzw. Tabellen benötigt werden. Ein Beispiel, das bei fast jedem Belegimport vorkommt, ist die Referenznummer der Gegenstelle, die sowohl im Feld RWEB_BEK.EXT_REFERENZ zwingend erforderlich ist, aber zur einfacheren Suche durch den Kunden auch in das Feld RWEB_BEK.BETREFF geschrieben werden soll.
Beispieldatei:
<Belegkopf><Auftragsnummer>12345678</Auftragsnummer>
</Belegkopf>
<Belegkopf>
<Auftragsnummer>
RWEB_BEK.EXT_REFENRENZ| RWEB_BEK.BETREFF
</Auftragsnummer>
</Belegkopf>
In einem solchen Fall werden die Zielfelder durch ein Pipe Zeichen | getrennt hintereinander geschrieben. Dabei können beliebig viele Zielfelder in beliebig vielen Tabellen angegeben werden.
<Belegkopf>
<NAME>
RWEB_BEK.NAME1 | RWEB_BEK.LS_NAME1 |
RWEB_BEK.RE_NAME1 | RWEB_ADR.NAME1
</NAME>
</Belegkopf>
Ein Hinweis an dieser Stelle:
Leerzeichen und Zeilenumbrüche im Mapping werden von der Generischen Filiale automatisch herausgefiltert. Die damit verbundene Flexibilität sollte man nutzen, um das Mapping durch die Formatierung möglichst gut lesbar zu machen. Es entstehen gerade nach längeren Zeiträumen Änderungswünsche bzgl. des Mappings, daher ist die Zeit, die man in die Lesbarkeit steckt in der Regel sehr gut investiert.
Ein weiteres wichtiges Hilfsmittel für die Lesbarkeit und Dokumentation des Mappings sind Kommentare.
Diese werden in XML mit der Zeichenfolge <!– begonnen und mit –> geschlossen.
<!–Zusätzliche Informationen (Optional)–>
Der Generator für die CSV/Excel-Mappings fügt den oberen Standardkommentar automatisch bei jeder Spalte mit ein. Bei XML-Mappings kann mit derselben Schreibweise vor und nach einem Knoten ein Kommentar eingefügt werden.
Zusammensetzen von Feldern
Ein häufiger Fall ist, dass Werte aus mehreren Feldern zusammengesetzt werden müssen. So z.B. bei einem aus Vor- und Nachname zusammengesetztem Namen.
<Adresse>
<Vorname>Max</Vorname>
<Nachname>Mustermann</Nachname>
</Adresse>
Der Inhalt der beiden XML Knoten muss kombiniert werden und ins Feld Name1 gespeichert werden. Das Mapping dazu sieht folgendermaßen aus:
<Adresse>
<Vorname>RWEB_BEK.NAME1#2</Vorname>
<Nachname>RWEB_BEK.NAME1#1[ append, ', ' ]</Nachname>
</Adresse>
Als Erklärung dazu:
RWEB_BEK.NAME1 gibt an, dass die Werte in das entsprechende Datenbankfeld geschrieben werden.
Die Raute teilt dem Import mit, dass das Feld zusammengesetzt werden muss und die Zahl dahinter gibt die Reihenfolge an. #1 bedeutet also, dass der Nachname der erste Teil des Feldes ist und der Vorname mit #2 als zweiter Teil angehangen wird.
Dann wären da noch die eckigen Klammern und das append: Damit werden nach dem Nachnamen ein Komma und ein Leerzeichen eingefügt. (Mehr dazu im nächsten Abschnitt)
Als Ergebnis wird in Name1 dann „Mustermann, Max“ eingetragen.
String-Funktionen
Der Import interpretiert zunächst alle eingelesenen Werte als Strings (Zeichenketten). Fast alle Programmiersprachen liefern eine Reihe von Standardfunktionen, Strings zu bearbeiten. Diese Funktionen dienten als Vorlage für die String-Funktionen der Generischen Filiale, die im gleichnamigen Menü zu finden sind.
Der grundsätzliche Syntax-Aufbau ist bei allen String-Funktionen gleich:
Hinter das Datenbankfeld, in das der Wert geschrieben werden soll, werden in eckigen Klammern der Name der String-Funktion und gegebenenfalls die Parameter angehängt.
Das erste Beispiel hatten wir schon im vorherigen Abschnitt – append:
<Adresse>
<Vorname>RWEB_BEK.NAME1#2</Vorname>
<Nachname>RWEB_BEK.NAME1#1[ append, ', ' ]</Nachname>
</Adresse>
Die Klammern schließen die Funktion ein, append gibt an welche Funktion ausgeführt wird und zwischen den beiden Hochkommata steht der Text, der angehangen werden soll.
Die am häufigsten verwendete Funktion ist replace:
<Preis>9.99 EUR</Preis>
Die replace-Funktion kann z.B. genutzt werden, um Preise in andere Formen zu überführen (Dezimalschreibweise mit Komma oder Punkt, Währung angehängt oder nicht)
<Preis>
RWEB_BEP.EINZELPREIS[ replace, '.', ',' ] [ replace, ' EUR', '']
</Preis>
Die Funktion replace hat zwei Parameter: Der erste ist der Text, der ersetzt werden soll und der zweite der neue Text.
Beim ersten replace wird der Punkt durch ein Komma ersetzt.
Wir erhalten also: 9,99 EUR
Beim zweiten replace wird ‘ EUR‘ durch den leeren String ” ersetzt, bzw. schlicht entfernt. Wichtig ist, dass vor dem “E” noch ein Leerzeichen steht, damit dieses ebenfalls entfernt wird. Beim zweiten Parameter, dem leeren String werden zwei Hochkommas direkt hintereinander geschrieben, ohne Leerzeichen dazwischen.
Wir erhalten: 9,99
Die String-Funktionen werden von links nach rechts nacheinander auf den zu importierenden Text angewendet und es können beliebig viele Funktionen kombiniert werden.
Alternativ zu oberen Version wäre auch folgende Lösung möglich:
<Preis>
RWEB_BEP.EINZELPREIS[ replace, '.', ',' ] [ substring , 1 , n-4]
</Preis>
Zunächst wird wieder der Punkt durch ein Komma ersetzt.
Substring dient dazu Teilstrings aus dem Text bzw. den Ausgangsdaten zu entnehmen. Der erste Parameter gibt an, ab welchem Zeichen gelesen wird und der zweite, wie viele Zeichen gelesen werden, wobei n als Platzhalter für die Gesamtlänge des Textes steht. Es wird ab dem ersten Zeichen gelesen und insgesamt werden 4 Zeichen weniger gelesen, als der Text lang ist.
Unterm Strich werden also die letzten 4 Zeichen entfernt was genau dem ‘ EUR’ entspricht, das entfernt werden soll. Der Vorteil ist, dass bei der zweiten Version die Groß-/Kleinschreibung keine Rolle spielt und beispielsweise auch ein ‘ GBP’ entfernt werden würde. Sollte die Währungsangabe hingegen fehlen, würden allerdings Ziffern entfernt und aus 100000 würde 10 werden.
Daher gibt es in diesem Zusammenhang keinen richtigen oder falschen Weg, sondern man muss den wählen, der am besten zu den gelieferten Daten bzw. den Variationen der Daten passt.
Die bisherigen Techniken können (und müssen teilweise) kombiniert werden, um auch komplexere Probleme zu lösen.
Zum Beispiel haben wir folgenden Preis gegeben:
<Preis>19999</Preis>
Laut der beiliegenden Dokumentation handelt es sich um ein numerisches Feld mit zwei Nachkommastellen ohne Dezimaltrennzeichen.
<Preis>
RWEB_BEP.EINZELPREIS#1 [ substring , 1 , n-2] [ append, ',' ]|
RWEB_BEP.EINZELPREIS#2 [ substring , n , -2]
</Preis>
Der Code sieht hier auf den ersten Blick etwas verwirrend aus, aber die Bedeutung ist recht leicht zu erklären.
Wir wissen, dass wir eine Ziffernfolge haben, von der die beiden letzten Ziffern hinter das Komma gehören und die anderen Ziffern vor das Komma.
Als erstes schneiden wir daher mit substring die beiden letzten Stellen ab und bekommen mit 199 den Wert vor dem Komma. Mit append hängen wir das Komma an und haben den ersten Teil unseres Preises 199, .
In der zweiten Zeile wird erneut substring verwendet, allerdings starten wir diesmal beim letzten Zeichen n und zählen mit -2 zwei Zeichen nach vorne, wodurch wir die beiden Nachkommastellen 99 erhalten.
Am Ende werden dann beide Teile zum Preis “199,99” kombiniert.
Die Variation von Substring muss man nicht auswendig lernen. Dafür bietet das Kontextmenü des Mappingeditors passende Vorlagen.
Jedenfalls zeigt das Beispiel sehr gut, wie man die verschiedenen Funktionen kombinieren kann und dass sich aus den recht simple Bausteinen auch komplexere Funktionen zusammenbauen lassen.
Neben den Preisen sind auch Datumsangaben immer wieder ein Problem, da es hier unzählige Schreibweisen gibt.
<Datum>2017-09-04</Datum>
Da die Angaben normalerweise aus jeweils zwei Ziffern für Tag und Monat, und aus vier Ziffern für das Jahr bestehen, gibt es hier eine Hilfsfunktion, die wesentlich bequemer ist, als der oben beschriebene Weg für Preise.
<Datum>RWEB_BEK.BELEGDATUM[ convertDate, 'JJJJ-MM-TT' ]</Datum>
Die Funktion convertDate bekommt als Parameter das Format des Datums in der Datei und passt das Format dann selbstständig an.
Wie bereits in der Einleitung erwähnt, gibt es eine Vielzahl von Funktionen, daher an dieser Stelle noch mal der Verweis auf das Kontextmenü und die eingebaute Hilfe des Mappingeditors.
Nachselektieren von Daten
Ein Trend, der gerade bei größeren Firmen zu beobachten ist, ist das bei der Übertragung der Daten die Daten auf ein Minimum reduziert werden. Bei Großhändlern, die regelmäßig ihre Großkunden beliefern, werden zum Beispiel anstelle der Adresse nur noch Referenznummern übermittelt.
Technisch ist dies durchaus sinnvoll, da damit unnütze Datenmengen vermieden werden und durch die Verwendung von eindeutigen Referenzen eine eindeutige Zuordnung der Daten gewährleistet wird.
Bei einem Kunden der regelmäßig beliefert wird, ist die Adresse in der Datenbank hinterlegt und um zu wissen, an wen die Ware geliefert werden soll, reicht es aus, die Kundennummer zu übermitteln.
Leider reicht dem Webshopimport diese Information nicht, daher müssen beim Import über die Generische Filiale alle Adressfelder gefüllt werden. Hier ist die Funktion Multiplefields hilfreich.
Im Mapping wird als Zielfeld für die Kundennummer das virtuelle Feld MULTIPLEFIELDS.ADRESSE angegeben.
<Kundennr>MULTIPLEFIELDS.ADRESSE</Kundennr>
Im Tab “SQLs” wird dazu der folgende Block eingetragen:
<SQLS>
<MULTIPLEFIELDS.ADRESSE>
<QUERY>
SELECT
ID
,ADRESSNR
,ANREDE
,NAME1
,NAME2
,NAME3
,STRASSE
,LKZ
,PLZ
,ORT
FROM ADR where KUNDENNR =:value
</QUERY>
<FIELDS>
<FIELD>RWEB_BEK.ADR_ID=ID</FIELD>
<FIELD>RWEB_BEK.ADRESSNR=ADRESSNR</FIELD>
<FIELD>RWEB_BEK.NAME1=NAME1</FIELD>
<FIELD>RWEB_BEK.NAME2=NAME2</FIELD>
<FIELD>RWEB_BEK.NAME3=NAME3</FIELD>
<FIELD>RWEB_BEK.ANREDE=ANREDE</FIELD>
<FIELD>RWEB_BEK.STRASSE=STRASSE</FIELD>
<FIELD>RWEB_BEK.LKZ=LKZ</FIELD>
<FIELD>RWEB_BEK.PLZ=PLZ</FIELD>
<FIELD>RWEB_BEK.ORT=ORT</FIELD>
</FIELDS>
</MULTIPLEFIELDS.ADRESSE>
</SQLS>
Diesen Block kann man sich mit dem Makro “adresse” gefolgt von Umschalttaste und Leertaste automatisch als Vorlage laden lassen.
Zur Erklärung:
Im Query-Teil selektieren wir uns per SQL die notwendigen Felder. Der Parameter :value enthält dabei den Wert aus der XML Datei, also in diesem Beispiel die Kundennummer.
Im unteren Teil Fields werden dann die Felder, die in der Query selektiert wurden den Datenbankfeldern zugeordnet.
Zur Bezeichnung: Das MULTIPLEFIELDS ist als Schlüsselwort für den Import fest vorgegeben. Den zweiten Teil nach dem Punkt kann man frei und sollte man vor allem sinnvoll wählen, um z. B. neben der Hauptadresse auch Liefer- und Rechnungsadresse zu füllen.
Zeitsteuerung
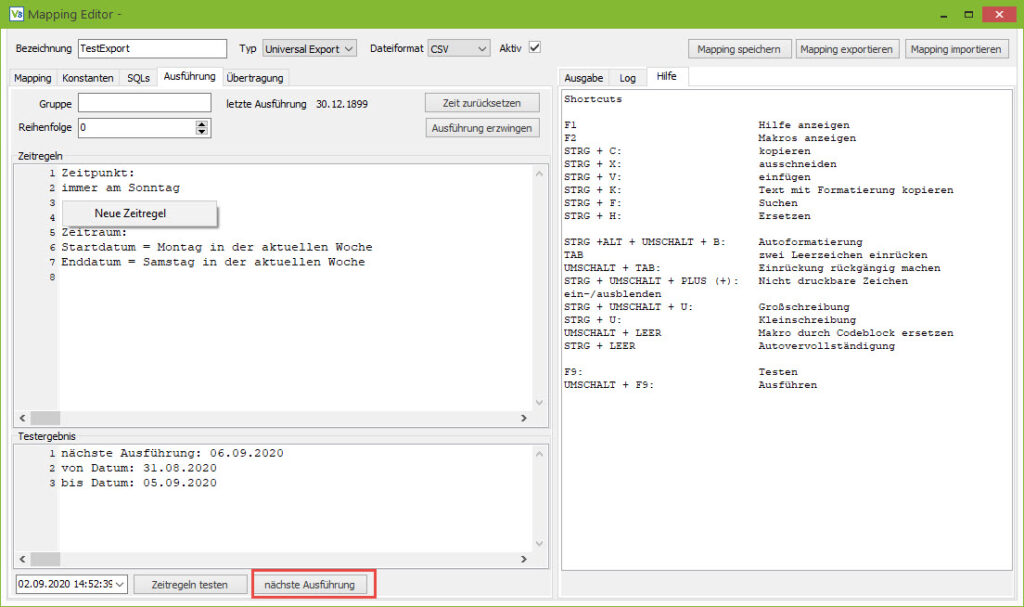
Die Generische Filiale bietet eine recht umfangreiche Zeitsteuerung. Der Zeitpunkt zu dem die Mappings ausgeführt werden, wird dabei mit Regeln definiert, die an die natürliche Sprache angelehnt sind.
Die Regeln für die Zeitsteuerung werden im Tab Ausführung definiert.
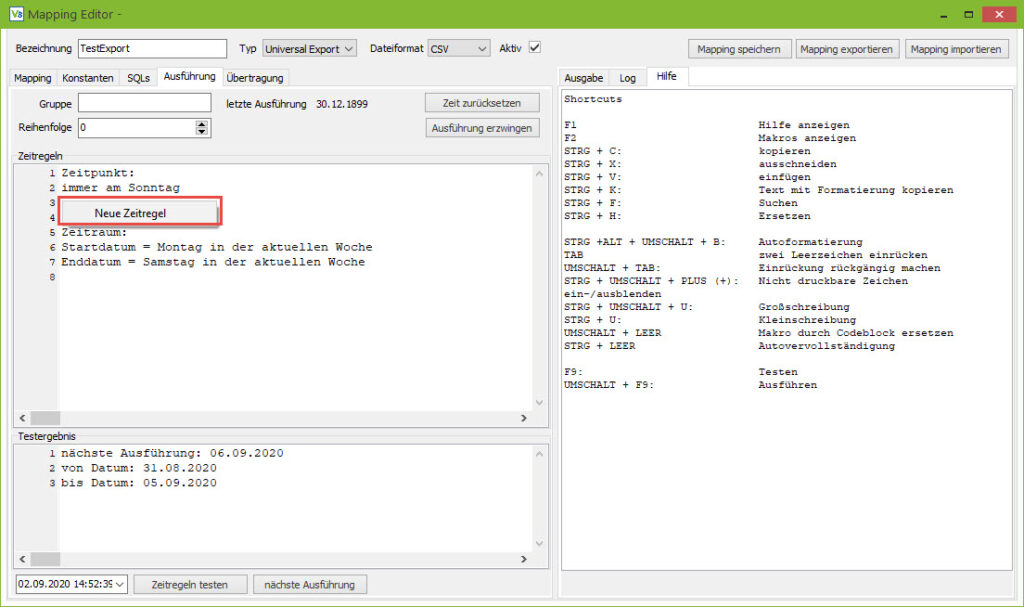
Das Beispiel auf dem Screenshot zeigt die Regeln für einen Belegexport, der sonntags die Belege der Woche (Montag bis Samstag) exportiert. Sonntags ist Wochenende und es werden keine Belege gebucht.
Die Regeln bestehen aus zwei Abschnitten:
Der Abschnitt Zeitpunkt legt fest, wann das Mapping ausgeführt werden soll. Der zweite Abschnitt dient dazu, einen Zeitraum zu definieren, um z. B. Belege die exportiert werden sollen zeitlich einzugrenzen.
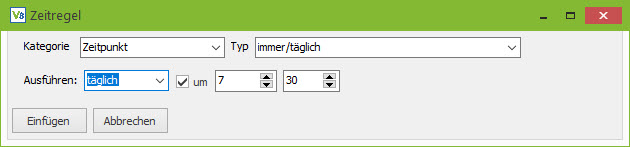
Mit einem Rechtsklick in das Editorfeld kann ein Assistent geöffnet werden, der die möglichen Regeln als Lückentext darstellt und Regeln einfügt. Der Assistent führt keine Prüfung des Datums durch. Das Mapping am 31. Februar auszuführen ist leider nicht möglich.
Zunächst zum Zeitpunkt:
Die Mappings werden vom Replikationsserver verarbeitet, der in einer Endlosschleife alle x-Minuten den Mappinghandler der Generischen Filiale aufruft. Die Zeitsteuerung prüft dann, ob das Mapping am jeweiligen Tag ausgeführt werden soll und ob es schon ausgeführt wurde. Die optionale Uhrzeitangabe gibt an, ab wieviel Uhr das Mapping zur Verarbeitung freigegeben wird. Ein Mapping, das um 18:00 Uhr ausgeführt werden soll, wird daher bei einem Intervall von 60 Minuten gegebenenfalls erst um 18:59 ausgeführt.
Mögliche Regeln
„Immer“ deaktiviert die Zeitsteuerung der Generischen Filiale und das Mapping wird bei jedem Durchlauf des Replikationsservers ausgeführt.
“Täglich” führt das Mapping einmal am Tag aus.
Daneben gibt es noch folgende Regeln:
Immer am Montag
Immer am 1. des Monats
Immer am Ultimo des Monats
Immer am 1. Montag des Monats
Immer am letzten Montag des Monats
Die fett hervorgehobenen Platzhalter können nach Bedarf durch den gewünschten Wochentag ersetzt werden. Anstelle des Monats kann auch “des Quartals” bzw. “des Jahres” verwendet werden.
Es können auch mehrere Regeln unter einander geschrieben werden:
Zeitpunkt:
Immer am Montag
Immer am Mittwoch
Immer am 1. des Monats
Immer am 15. des Monats
Nach der Definition des Zeitpunkts folgt die Definition des Zeitraums. Bei einigen Exporten sollen Daten aus einem bestimmten Zeitraum z. B. die Rechnungen der Vorwoche bzw. des Vormonats exportiert werden.
Über die Zeitregeln können Regeln zum Berechnen eines Start- und Enddatums definiert werden. Die berechneten Daten stehen dann in den SQLs als Parameter :vonDatum und :bisDatum zur Verfügung.
Der Zeitraum wird immer ausgehend vom Datum, an dem das Mapping ausgeführt wird, berechnet.
Ein Sonderfall sind Bedingungen für den Wochen-, Monats-, Quartals bzw. Jahreswechsel.
Zeitraum:
Startdatum = Montag in der letzten Woche
Enddatum = Sonntag in der letzten Woche
Wenn Monatswechsel in den letzten 7 Tagen
Enddatum = ultimo im letzten Monat
Normalerweise wird jeweils ein Start- und Enddatum angegeben. In einigen Fällen sollen allerdings bei einem Monatswechsel nur die Rechnungen bis zum Monatsende übertragen werden. In solchen Fällen wird die Bedingung definiert und danach, wie das Datum in diesem Spezialfall berechnet werden soll.
Hinweis 1: Für größere Zeiträume z. B. 100 Tage bei denen die Schreibweise
vorvorvor…vorgestern unpraktikabel wäre gibt es eine alternative Syntax aus der Anfangszeit der Generischen Filiale, die nur verwendet werden sollte, wenn es nicht anders geht.
Hinweis 2: Der Zeitraum macht nur beim Export Sinn, allerdings muss er auf Grund der Arbeitsweise des Parsers auch beim Import mit angegeben werden. Am besten lässt man das standardmäßige Startdatum=gestern und Enddatum=gestern unverändert.
Testen
In der unteren Hälfte des Tabs können die Zeitregeln getestet werden. Dabei kann sowohl geprüft werden, ob das Mapping am gewählten Datum ausgeführt wird, als auch wann es ausgehend vom Testdatum zum nächsten Mal ausgeführt wird. Der Zeitraum wird ebenfalls ausgehend vom Testdatum berechnet und angeben.
Deaktivieren der Zeitsteuerung
Der Mappinghandler speichert den Zeitpunkt, zu welchem ein Mapping zum letzten Mal ausgeführt wurde und verhindert, dass ein Mapping mehrfach am selben Tag ausgeführt wird. Kam es bei der Verarbeitung eines Mappings zu einem Fehler und das Mapping soll dann nach Korrektur ein zweites Mal ausgeführt werden, dann lässt sich die Zeitsteuerung einmalig deaktivieren.
Über den Button „Zeit zurücksetzen“ wird dem Mappinghandler mitgeteilt, dass das Mapping heute noch nicht ausgeführt wurde.
Soll das Mapping an einem Tag ausgeführt werden, an dem es normalerweise nicht ausgeführt wird, dann lässt sich über den Button „Ausführung erzwingen“ der über die Zeitsteuerung gespeicherte Zeitpunkt überspringen und die Ausführung sofort starten. Die nächste Ausführung erfolgt dann wieder passend zu den Regeln, die in der Zeitsteuerung hinterlegt sind.
Wichtig ist es in beiden Fällen das Mapping beim Schließen des Editors zu speichern, damit die Änderung auch in die Datenbank geschrieben wird. Alternativ kann das Mapping über den Button ausführen im Tab “Log” auch direkt aus dem Editor heraus ausgeführt werden.